


Spotlight Presentation: Foundational model building with single-cell RNA-Seq data
26 Sept 2024
Data Quality
Target Identification
Lead Generation & Optimization
Drug Response Prediction
)
Strand will present progress on the following subproblems in the use of single-cell RNA-Seq data for drug discovery:
-
An AWS data lake capable of ingesting and processing single-cell RNA-Seq data with associated metadata at scale
-
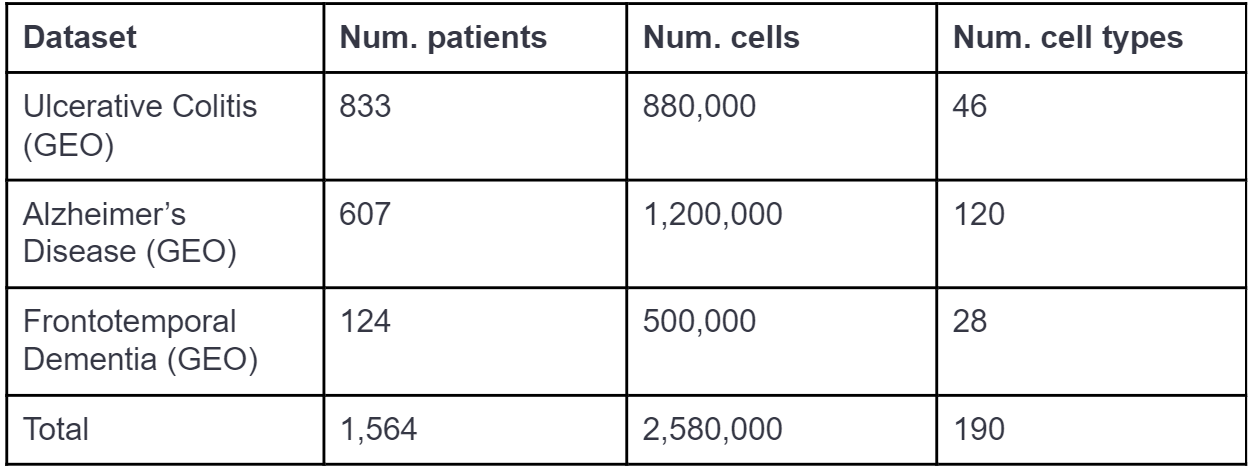
Semi-automated LLM-based ingestion to a schema with ≈35 fields of single-cell RNA-Seq + metadata of 3 disease datasets -- UC, AD and FTD -- from GEO. We show an improvement in turnaround time of ≈3x-5x
-
A standardized single-cell pipeline that generates normalized counts from fastqs for ingested data
-
Embeddings of the single-cell data for pretraining on an LLM [see for e.g scBERT]. We show how such embeddings might be used to remove batch effect and hence integrate data.
